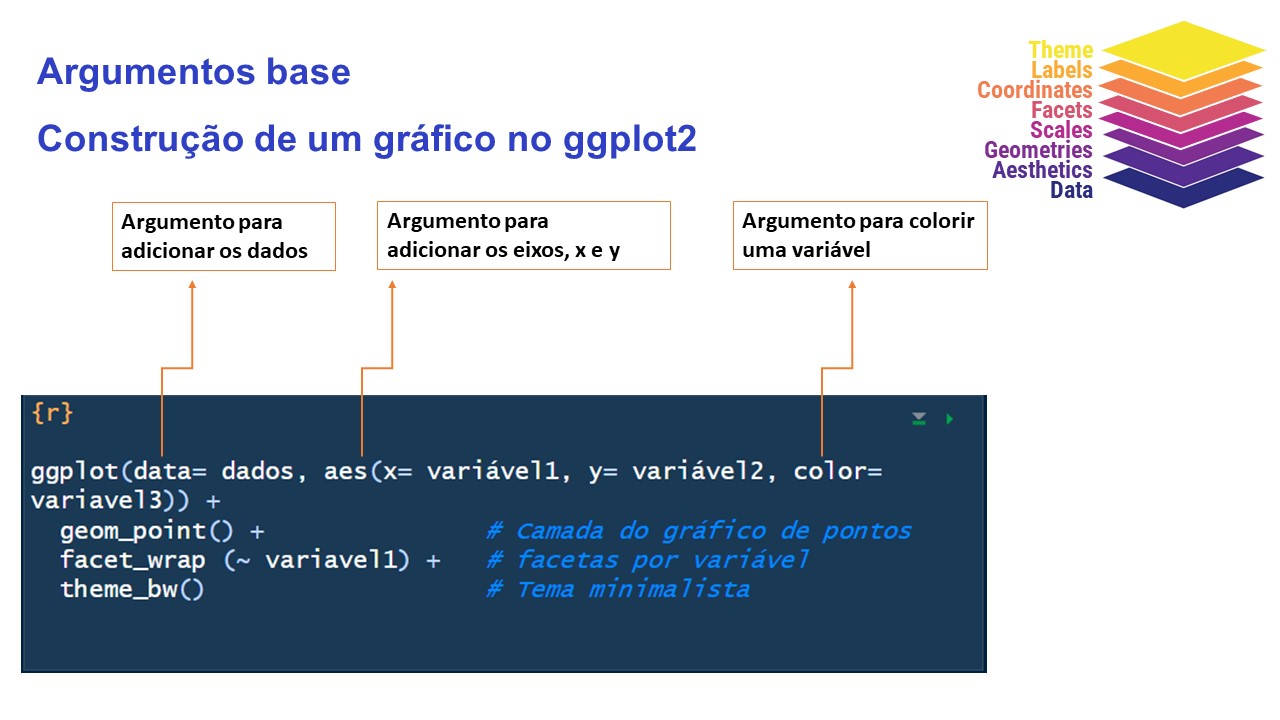
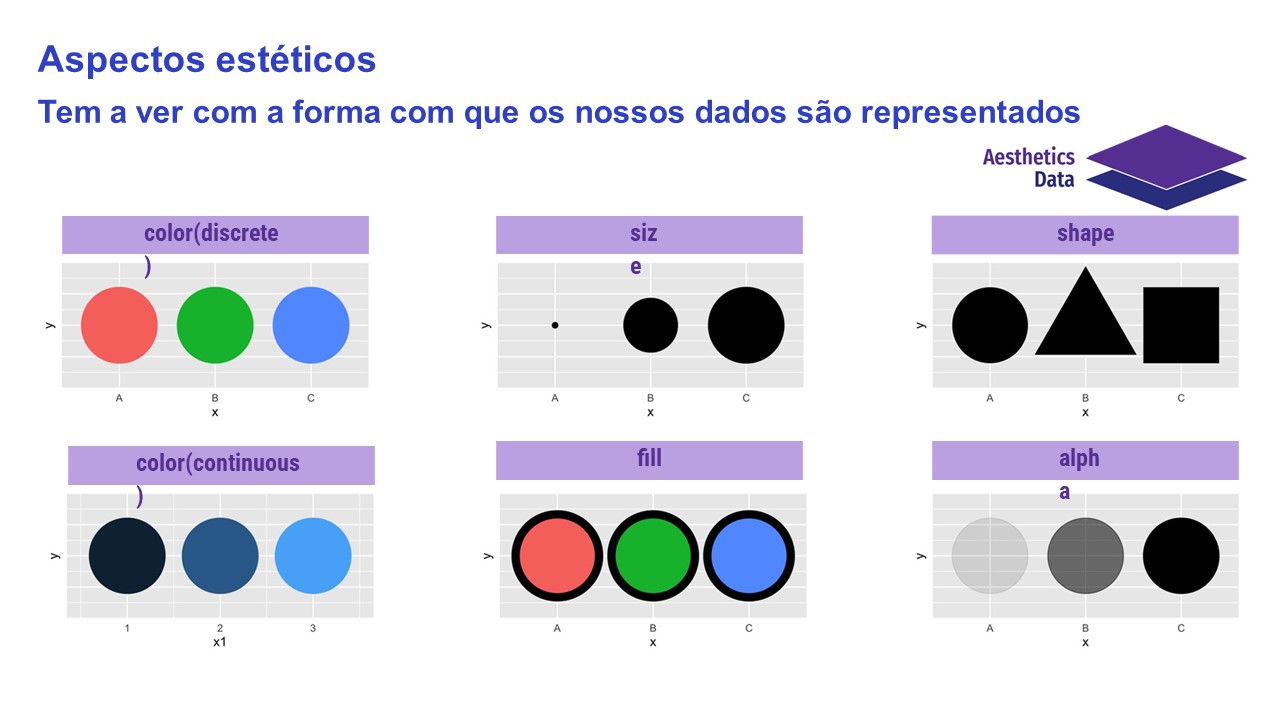
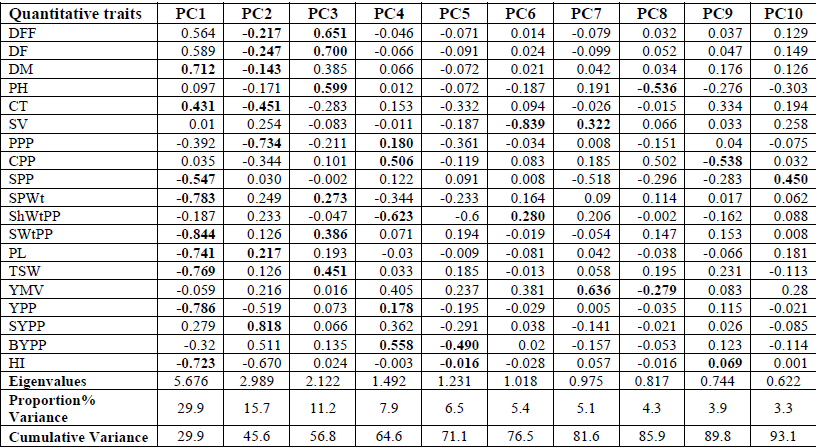
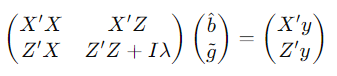Primeiro Script
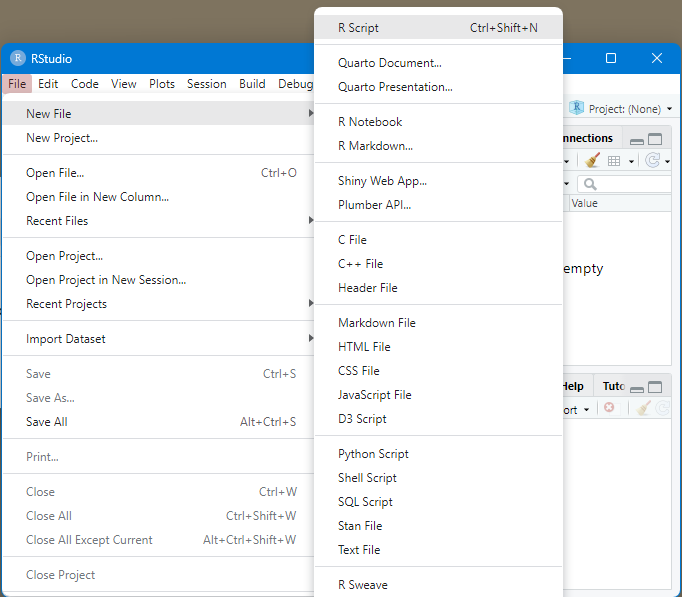
Para que você comece a escrever os códigos ou seja “programar”, é necessário criar um arquivo R Script. Veja como abrir este arquivo, clicando em:
File> New File > R Script.
ATALHO: Ctrl + Shift + N.
Primeiro Script
![]()
File> New File > R Script. Ou use o atalho Ctrl + Shift + N.
Ambientação no RStudio
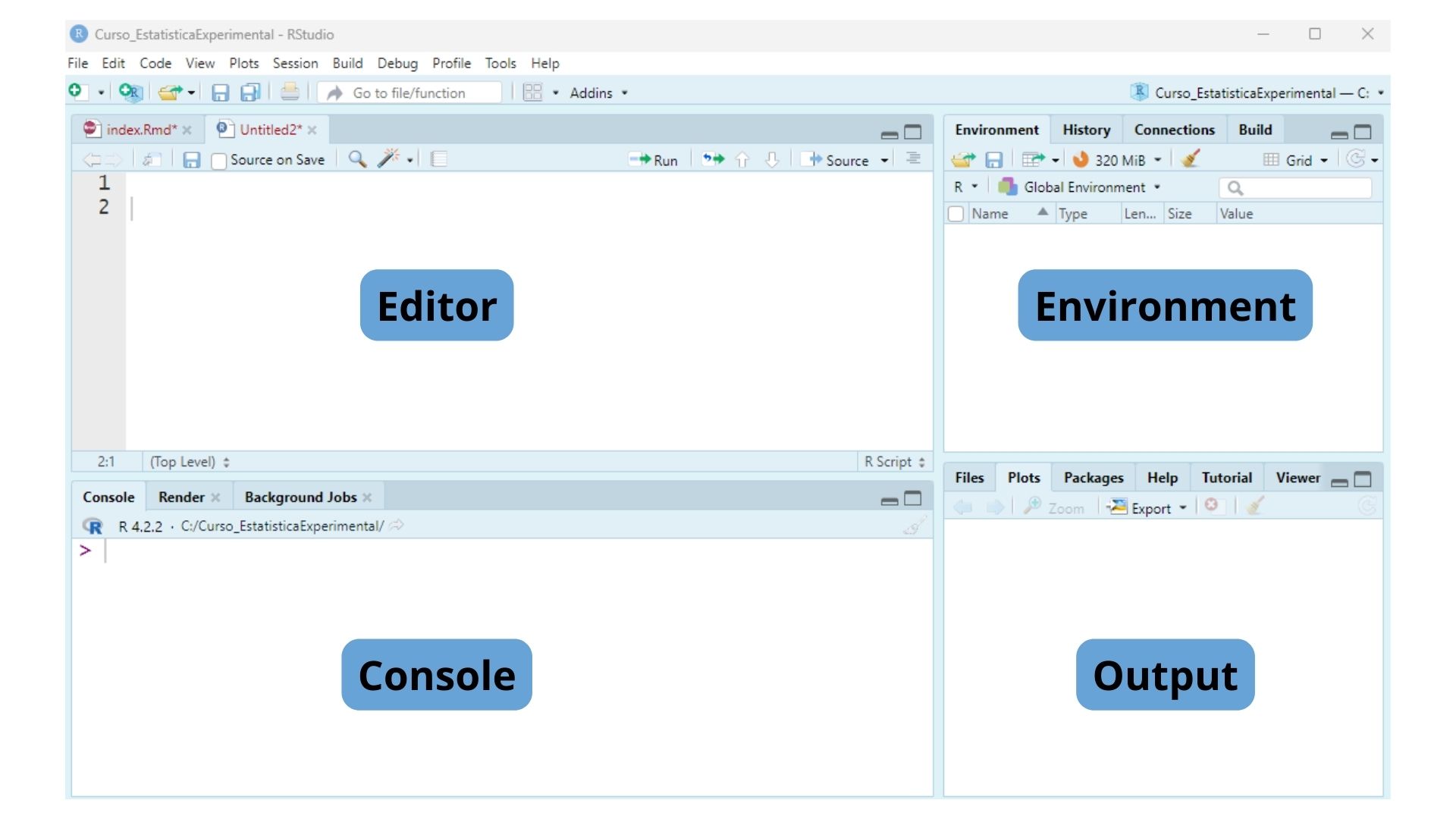
Este é o ambiente do RStudio, ele é representado por quatro quadrantes, o editor, console, environment e output. A organização desses quadrantes pode ser alterada como você preferir;
1. Editor : onde você irá escrever e editar os scripts em R;
2. Console: permite a execução dos comandos em R;
3. Output (saída): exibe os resultados das operações realizadas no console;
4. Environment (ambiente): mostra os objetos (variáveis, funções) disponíveis na sessão R.
Ambientação no RStudio
Quando você cria um novo arquivo de script R, um quarto painel deve aparecer no canto superior esquerdo do R Studio, como você pode ver na Figura abaixo. Salve esse arquivo na pasta que você escolher como código exemplo.
![]()
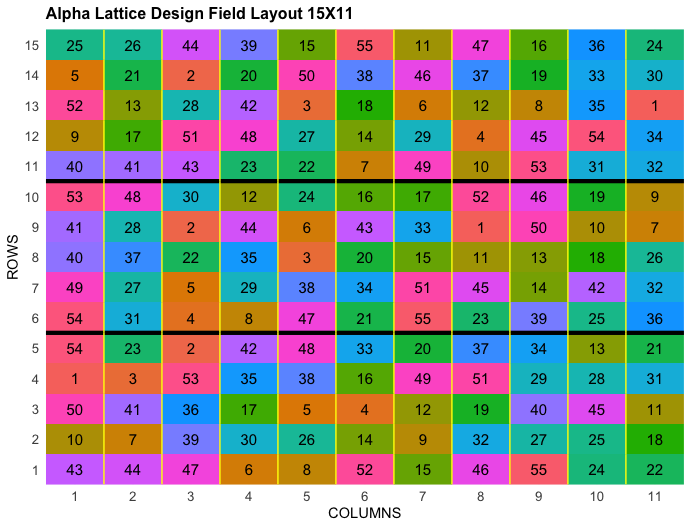
Delineamento em Alfa Láttice
Delineamento em Alfa Láttice
![]()
Delineamento em Alpha Láttice. 55 tratamentos, 3 repetições e 5 blocos incompletos.
Delineamento em Alfa Láttice
1Patterson e Williams (1976).
Nem todos os tratamentos aparecem em cada bloco.
Esse tipo de design é ideal para experimentos com um número elevado de tratamentos (genótipos/cultivares).
t = s*k
t: número de tratatamentos
r: número de repetições
k: número de blocos
s: número de blocos incompletos
Modelo
Yijk= μ + αi + βj + (1∣rep:inc.bloco)jk + ϵijk
onde:
Yijk: valor observado da variável resposta para o genótipo i na réplica j e bloco incompleto k.
μ: média geral do experimento.
αi: efeito fixo do genótipo i.
βj: efeito fixo da réplica j.
(1∣rep:inc.bloco)jk: efeito aleatório dos blocos incompletos dentro de cada réplica, onde “rep: inc.bloco” indica que os blocos estão aninhados nas réplicas.
ϵijk: erro aleatório associado a cada observação, assumido com distribuição normal N(0,σ2).
Modelos Lineares Mistos
Seleção de indivíduos superiores.
Corrige simultaneamente os dados para os efeitos ambientais, estima os parâmetros genéticos e prediz os valores genéticos.
Estimação dos componentes de variância - Restricted maximum likelihood REML.
Predição dos valores genéticos - Best linear unbiased prediction (BLUP).
Flexibilidade quanto ao balanceamento dos dados.
Modelos Lineares Mistos x ANOVA
| 1 |
Componentes da variância
ANOVA |
Componentes da variância
Restricted maximum likelihood REML |
| 2 |
Componentes da média
Média fenotípica via quadrados mínimos |
Componentes da média
Média genética ou genotípica via Best linear unbiased prediction (BLUP) |
| 3 |
Teste de significância
Teste F da ANOVA |
Teste de significância
Teste de LRT via Qui quadrado |
Modelos estatísticos y= Xβ+Zγ+ϵ
- y: vetor de respostas observadas, ou seja, os valores da variável dependente.
Xβ: termo de efeitos fixos, onde:
X: é a matriz de variáveis explicativas (design matrix) para os efeitos fixos.
β: representa os coeficientes (parâmetros) de efeitos fixos, que são constantes para cada nível do fator fixo.
Zγ: termo de efeitos aleatórios, onde:
Z: é a matriz de variáveis explicativas para os efeitos aleatórios.
γ: são os coeficientes para os efeitos aleatórios, considerados variáveis aleatórias.
ϵ: vetor de erros aleatórios residuais, com média zero e variância σ2, representando a variação não explicada pelo modelo.
Efeitos do modelo
Efeito Fixo
Os níveis dos efeitos fixos são constantes e foram selecionados deliberadamente para o estudo.
A inferência e interpretação desses efeitos são válidas apenas para os níveis presentes no experimento, como um conjunto específico de tratamentos ou genótipos em um experimento.
Um exemplo é a comparação entre diferentes fertilizantes: os fertilizantes são níveis fixos, escolhidos intencionalmente.
Hipótese a ser testada: verificar se há diferenças significativas entre os níveis, H0:β1=β2=…=βn.
Efeitos do modelo
Efeito Aleatório
Os níveis dos efeitos aleatórios são amostras de uma população maior e são tratados como variáveis aleatórias.
A inferência é válida para toda a população da qual os níveis são amostrados, permitindo generalizações além dos níveis específicos do estudo.
Um exemplo é o uso de blocos incompletos em um experimento: cada bloco representa uma amostra da variabilidade espacial do campo.
Hipótese a ser testada: verifica se a variabilidade entre os níveis é significativa, formulada como H0:σ2= 0, onde σ2 é a variância do efeito aleatório.
Estimação dos componentes de variância
Restricted maximum likelihood- REML
Máxima verossimilhança restrita- REML
- Decompõe a variabilidade observada em diferentes componentes de variância.
y = Xb + Zg + Wp + e
Estimação dos componentes de variância
Restricted maximum likelihood REML- Função da Distribuição Normal
Modelagem da variância genética e ambiental: assumimos como normalmente distribuidos. Para variáveis quantitativas, a variação ao redor de uma média esperada (como a média de produtividade) segue um padrão simétrico e contínuo, o que facilita a estimativa desses componentes.
O REML considera essa normalidade para gerar estimativas mais precisas de componentes da variância para dados balanceados ou desbalanceados.
É base por exemplo, para calcular a probabilidade de que a diferença entre genótipos se deva a variação genética e não a erros experimentais (modelagem assumindo a distribuição normal).
\[
f(x)=\frac{1}{\left(\sigma \sqrt{2\pi }\right)}\cdot e^{\left(\frac{-1}{2}\left(\frac{(x-\mu )}{\sigma }\right)^{2}\right)}
\]
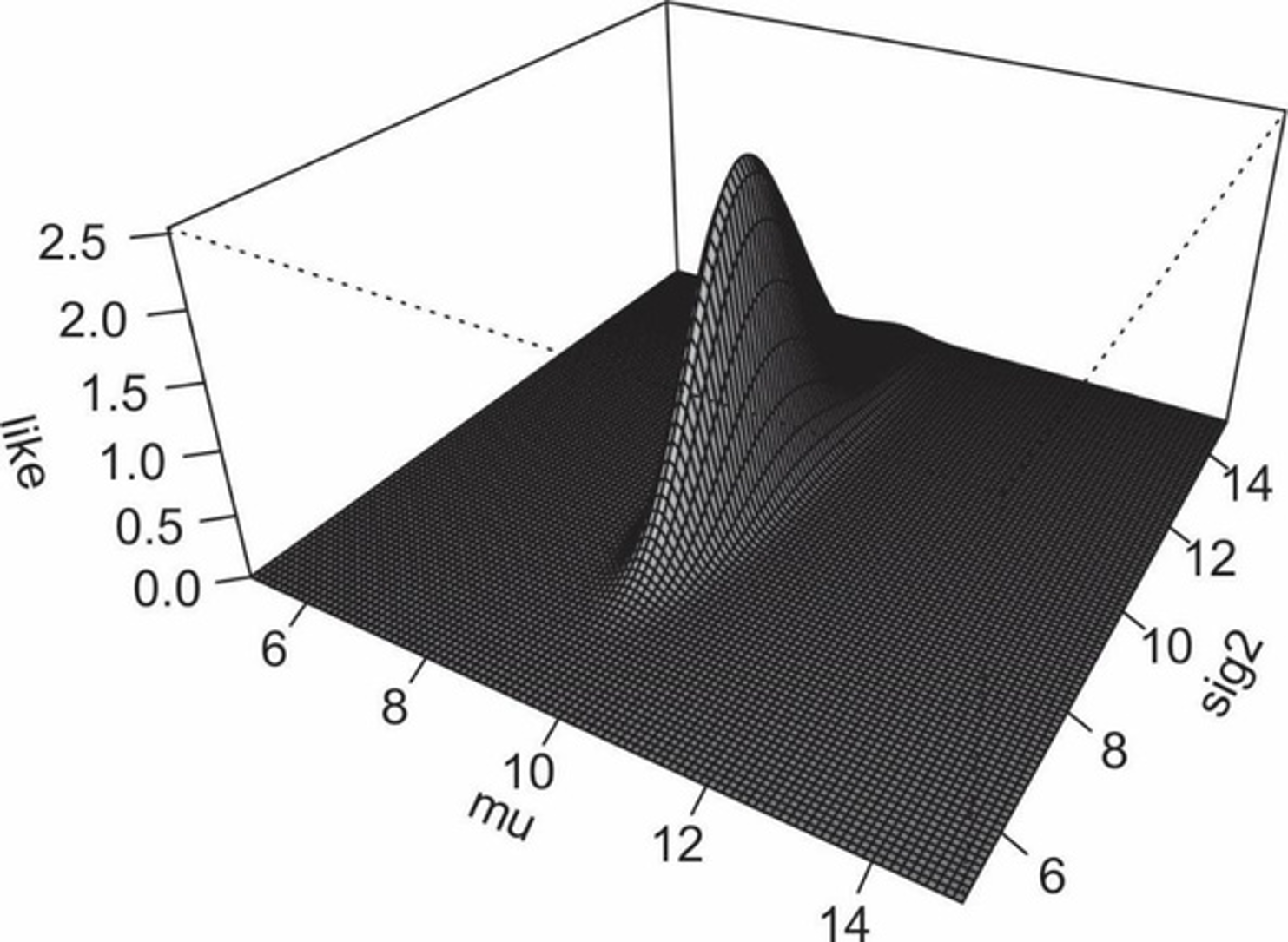
Estimação dos componentes de variância
Superfície tridimensional de uma função de verossimilhança (REML)
Essa superfície representa a probabilidade de observar os dados para diferentes valores dos parâmetros μ e σ2 na distribuição normal.
Eixo μ: representa possíveis valores para a média dos dados.
Eixo σ2: representa a variância dos dados (g + ge + res).
Eixo like: pontos mais altos indicam combinações de μ e σ2 que tornam os dados observados mais prováveis. O REML busca maximizar essa função para obter as estimativas de μ e σ2 plausíveis.
![]()
Predição de valores genéticos
Best linear unbiased prediction- BLUP
Melhor previsão linear imparcial - BLUP
Predição de valores genéticos
Best linear unbiased prediction- BLUP
y = Xb + Zg + e
![]()
X e Z são matrizes de design que relacionam observações com efeitos fixos e aleatórios, respectivamente.
b representa os coeficientes dos efeitos fixos (por exemplo, efeitos ambientais).
g representa os valores genéticos dos efeitos aleatórios (genótipos).
λ é o fator de ponderação que depende da razão entre variância residual e variância genética. ʎ = (1-ℎ2 ) / ℎ2
y é o vetor de observações (dados fenotípicos).
Predição de valores genéticos
Best linear unbiased prediction- BLUP
![]()
![]()
REML
| \(\sigma_g^2\) |
25.3 |
| \(\sigma_res^2\) |
8.6 |
| \(\sigma_p^2\) |
33.5 |
| \(h^2 = \frac{\sigma_g^2}{\sigma_p^2}\) |
0.78 |
| μ |
15 |
BLUP/BLUE
BLUP: Predição de efeitos aleatórios, como valores genéticos, levando em conta a variabilidade genética e a herdabilidade do caráter.
*BLUE: Estimativa de parâmetros fixos, como médias ou coeficientes de efeitos fixos. (b1 e b2)
| Efeito |
BLUP | BLUE |
| g1 |
5.5 |
| g2 |
4.9 |
| g3 |
5.0 |
| g4 |
-3.3 |
| g5 |
-5.0 |
| *b1 |
10.0 |
| *b2 |
12.3 |
Acurácia seletiva
- Acurácia Seletiva: avaliar o quão confiável é a predição do valor genético de um indivíduo.
Erro de predição (PEV) ou herdabilidade
\(\hat{r}_{\hat{g}g} = \sqrt{1 - \frac{\text{PEV}}{\sigma_g^2}}\)
\(\hat{r}_{\hat{g}g} = \sqrt{h^2}\)
1 Classificação:
- Baixa (0 0.15) | Moderada (0.15-0.50) | Alta (0.50-0.80) | Muito alta (0.80-1)
Herdabilidade
Representa uma proporção da variabilidade existente em uma população segregante que é de natureza genética.
Quanto maior a herdabilidade maior o controle genético.
Indica a facilidade de se praticar o melhoramento daquele carácter.
\(h^2 = \frac{\sigma_g^2}{\sigma_p^2}\)
\(\sigma_g^2\): Variância genética
\(\sigma_p^2\):Variância fenotipíca