Que alegria ter você aqui para mais um café. Nesta edição especial, preparei uma seleção cuidadosa de recursos, pacotes e conexões que vão enriquecer sua jornada com R.
Pegue sua xícara favorita e vamos juntos explorar o que há de mais interessante no universo R!
☕ Assine o Café com R
Fique por dentro das aulas, conteúdos, newsletter!
Que cada gole desperte uma nova ideia.
Que cada script abra uma nova conversa.
Que o Café com R, se torne um ponto de encontro nosso!
Dose da Semana
Prepare sua xícara
Vamos explorar o que está acontecendo no universo R!
Eventos 2026: Marque sua agenda!
A comunidade R está vibrante em 2026! Aqui estão os principais eventos para você participar, aprender e se conectar:
# Instalaçãoinstall.packages("skimr")library(skimr)# Uso mais simplesskim(iris)
O que você ganha:
Estatísticas descritivas completas
Histogramas em miniatura (sparklines)
Contagem de valores ausentes
Separação automática por tipo de variável
skimr: Exemplo prático
library(skimr)library(dplyr)# Carregar dadosdata(starwars)# Resumo completoskim(starwars)# Resumo apenas de variáveis numéricasstarwars %>%skim() %>%filter(skim_type =="numeric")# Resumo agrupadostarwars %>%group_by(species) %>%skim()
skimr x summary()
Com summary():
Sepal.Length Sepal.Width Petal.Length
Min. :4.300 Min. :2.000 Min. :1.000
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600
Median :5.800 Median :3.000 Median :4.350
Mean :5.843 Mean :3.057 Mean :3.758
Com skim():
Todas as estatísticas acima +
Histograma visual de distribuição
Contagem de valores únicos e ausentes
Desvio padrão e quartis
Tudo organizado em uma tabela bonita
Quando usar skimr?
Cenários ideais:
Exploração inicial: Primeiro contato com um dataset novo
Relatórios automáticos: Documentação rápida das variáveis
Detecção de problemas: Identificar missing values, outliers
Apresentações: Mostrar overview dos dados de forma profissional
Quando usar skimr?
Dica: Use skim() no começo de todo script de análise. Você vai economizar tempo e evitar surpresas depois.
Pacote 2: janitor
Limpeza de dados sem dor de cabeça
O pacote janitor é seu melhor amigo quando os dados estão bagunçados (e quase sempre estão!).
library(janitor)library(dplyr)# Remover linhas e colunas completamente vaziasdf %>%remove_empty(c("rows", "cols"))# Remover linhas duplicadasdf %>%get_dupes()# Criar tabelas de frequênciadf %>%tabyl(categoria) %>%adorn_totals("row") %>%adorn_percentages("col") %>%adorn_pct_formatting()# Arredondar todos os números de uma vezdf %>%mutate(across(where(is.numeric), ~round(., 2)))
Além da newsletter, David criou uma plataforma completa de aprendizado:
Recursos disponíveis:
Cursos online: Do básico ao avançado
Templates prontos: Relatórios e apresentações
Consultoria: Para organizações que querem adotar R
Comunidade: Fórum ativo de alunos
Filosofia: “R para o resto de nós” — torna R acessível para quem não é programador de formação, como pesquisadores, analistas e profissionais de diversas áreas.
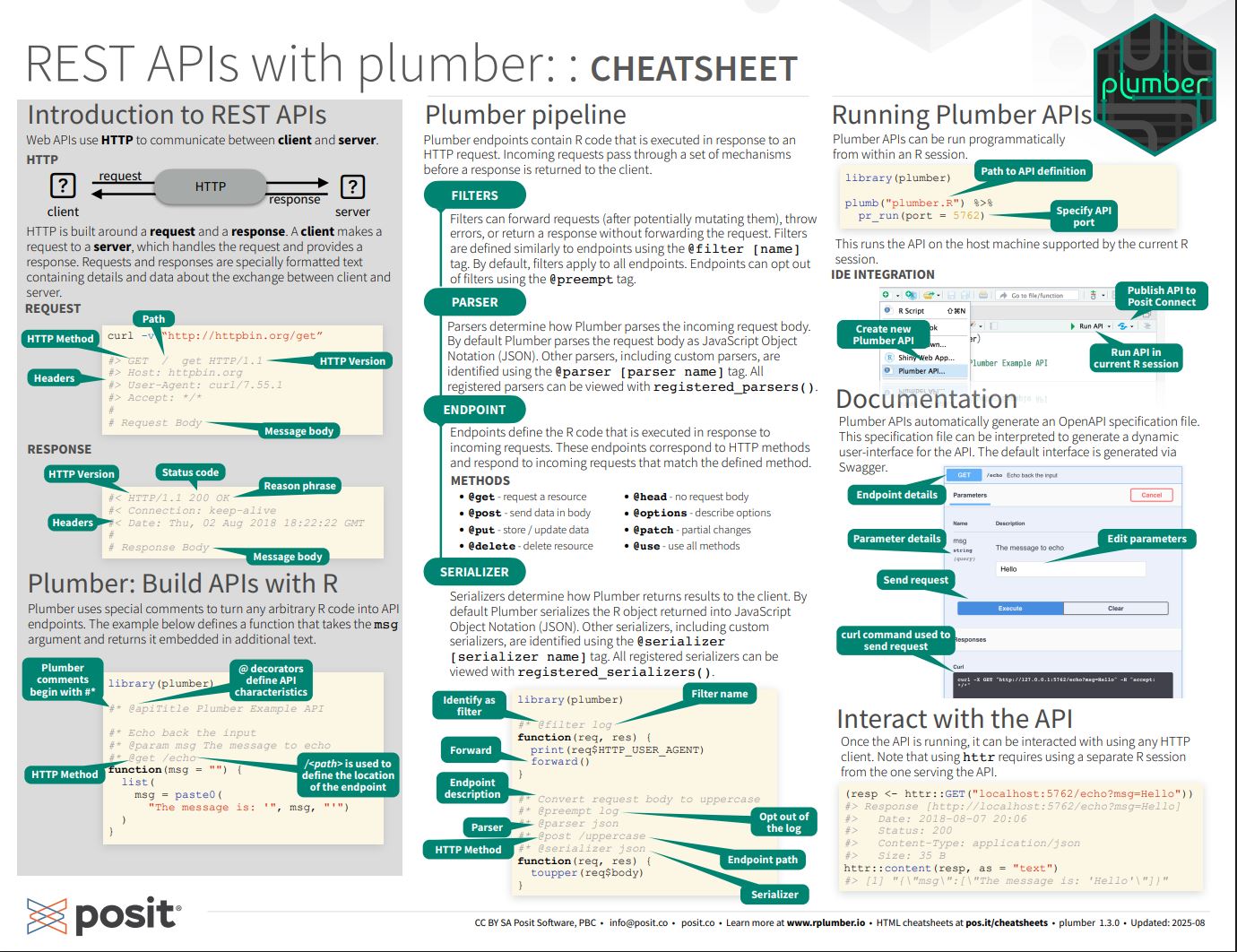
Cheatsheets (folhas de cola) são guias visuais de 1-2 páginas que resumem as funções e sintaxe dos principais pacotes do R.
O que são as Cheatsheets?
Disponíveis para:
Básico: Base R, RStudio IDE
Tidyverse: dplyr, ggplot2, tidyr, purrr, stringr
Dados: readr, lubridate, forcats
Modelagem: caret, tidymodels
Visualização: ggplot2, shiny, leaflet
Comunicação: R Markdown, Quarto
E muito mais!
Como usar as Cheatsheets efetivamente
Estratégias de uso:
Imprima as essenciais: Deixe ao lado do computador
Salve no computador: Organize por pasta de projetos
Consulte durante o código: Tenha sempre abertas em outra tela
Use para aprender: Descubra funções que você não conhecia
Conversa de Café
Reflexões sobre nossa jornada
A jornada do aprendizado contínuo
Chegamos ao final dessa edição, mas essa é apenas uma pausa no nosso café, não um adeus.
O que levamos daqui:
4 eventos imperdíveis para 2026
400 + livros gratuitos para explorar
2 pacotes que vão transformar seu fluxo de trabalho
3 criadores de conteúdo incríveis para seguir
Ferramentas de referência sempre à mão
A jornada do aprendizado contínuo
Mas mais importante que os recursos: Levamos a certeza de que não estamos sozinhos nessa jornada. A comunidade R é global, acolhedora e está sempre crescendo.
Allisson Horst.
Seu próximo passo
Não deixe esse conhecimento parado. Escolha APENAS UMAação para esta semana:
Opções:
Instalar e testar o pacote skimr no seu próximo projeto
Inscrever-se em um dos eventos de 2026
Explorar um livro do Big Book of R
Seguir um dos criadores recomendados
Baixar 3 cheatsheets essenciais
Lembre-se
Progresso consistente vale mais que perfeição. Um gole de cada vez.
Criei esse espaço par isso! Respire, pare, pense, continue, respeite-se!
Feedback
Seu feedback importa!
Tem sugestões de temas? Quer compartilhar seu projeto?
Quer ver algum pacote específico na próxima edição?
Responda essa newsletter ou me envie uma mensagem (LinkedIn). Adoro ouvir de vocês!
☕ Assine o Café com R
Fique por dentro das aulas, conteúdos, newsletter!
Que cada gole desperte uma nova ideia.
Que cada script abra uma nova conversa.
Que o Café com R, se torne um ponto de encontro nosso!