Pacotes essenciais no R que transformam seu trabalho com dados
R
Pacotes
Tidyverse
Ferramentas
Descubra os pacotes que vão elevar sua análise de dados a outro nível
Author
Jennifer Luz Lopes
Published
December 2, 2025
Esta é a quarta edição do Café com R
Seja bem-vinda(o)!
Aqui é uma pausa para falar de dados.
Toda semana vamos nos encontrar por aqui para conversar sobre ciência de dados, estatística e muito mais de um jeito leve e prático.
Toda semana, uma dose de código, reflexão e boas ideias com R, um café de aprendizagem por vez.
Sobre a Newsletter de hoje
Pessoal, trouxe pacotes variados que uso no dia a dia para diferentes etapas do trabalho com dados.
Preparei esta edição pensando em você que quer conhecer as ferramentas certas para cada etapa do seu trabalho com dados. Não adianta ter o melhor café se não temos os utensílios certos para prepará-lo, não é mesmo? Hoje vamos da semente à xícara para explorar o ecossistema de pacotes do R que realmente fazem diferença no dia a dia. Espero que seja útil para você ou para alguém que conheça!
Organizei os pacotes por área de aplicação: desde a importação dos dados até a modelagem avançada, passando pela limpeza, transformação e visualização. Cada fpacote foi escolhido porque resolve problemas reais e torna o trabalho mais eficiente e reproduzível.
Na Dose da Semana, você vai encontrar exemplos práticos de cada pacote, com código funcional que você pode adaptar aos seus projetos.
E no quadro Para Acompanhar o Café, selecionei recursos e documentações que vão aprofundar seu conhecimento em cada área.
Ótima leitura!
Ahhh pega seu café aí!
Essa é a minha gatinha meguy, piscando para você!
Pacotes essenciais no R
tidyr : Organizando seus dados
O tidyr é o pacote especialista em transformar dados “bagunçados” em formato tidy (organizado). Se você já recebeu planilhas com dados espalhados por várias colunas quando deveriam estar em linhas (ou vice-versa), este é o pacote que vai salvar seu dia.
Principais funções:
pivot_longer(): transforma dados de formato “wide” para “long”
pivot_wider(): o inverso, de “long” para “wide”
separate(): separa uma coluna em várias
unite(): une várias colunas em uma
drop_na(): remove linhas com valores faltantes
Exemplo:
Code
library(tidyr)library(dplyr)# Dados em formato "wide"dados_wide <-tibble(planta =c("A", "B", "C"),jan =c(12, 15, 14),fev =c(13, 16, 15),mar =c(14, 17, 16))# Transformando para formato "long" (tidy)dados_long <- dados_wide |>pivot_longer(cols = jan:mar,names_to ="mes",values_to ="crescimento")print(dados_long)
# A tibble: 9 × 3
planta mes crescimento
<chr> <chr> <dbl>
1 A jan 12
2 A fev 13
3 A mar 14
4 B jan 15
5 B fev 16
6 B mar 17
7 C jan 14
8 C fev 15
9 C mar 16
Quando usar: Sempre que seus dados não estiverem no formato “uma observação por linha, uma variável por coluna”. Fundamental antes de qualquer análise ou visualização.
Salve já essas funções se você ainda não usa!
readr: Importação de dados
O readr é o pacote do tidyverse para ler e escrever dados tabulares. Ele é muito mais rápido e consistente que as funções base do R, além de detectar automaticamente os tipos de dados.
Principais funções:
read_csv(): lê arquivos CSV
read_delim(): lê arquivos com delimitadores customizados
read_tsv(): lê arquivos separados por tabulação
write_csv(): escreve arquivos CSV
read_rds() / write_rds(): formato nativo do R
Exemplo:
Code
library(readr)# Lendo um CSVdados <-read_csv("meus_dados.csv")# Especificando tipos de colunadados <-read_csv("meus_dados.csv",col_types =cols(id =col_integer(),nome =col_character(),data =col_date(format ="%Y-%m-%d"),valor =col_double()))# Salvando processamentowrite_csv(dados_processados, "dados_limpos.csv")# Salvando em formato R nativo (mais rápido)write_rds(dados_processados, "dados.rds")
Quando usar: Logo no início de qualquer projeto, na importação dos dados. Economiza tempo e evita problemas de encoding e tipos de dados.
stringr : Manipulação de textos
O stringr torna a manipulação de strings no R muito mais intuitiva. Todas as funções começam com str_ e trabalham de forma consistente, diferente das funções base do R.
# Operações com datasinicio <-ymd("2025-01-01")fim <-ymd("2025-12-31")dias_decorridos <-as.numeric(fim - inicio)print(paste("Dias no ano:", dias_decorridos))
[1] "Dias no ano: 364"
Quando usar: Séries temporais, análise de eventos, cálculos de prazos, agrupamentos temporais.
ggplot2 : Visualização de dados
O ggplot2 é o padrão-ouro para visualização de dados no R. Baseado na “gramática de gráficos”, permite criar visualizações sofisticadas de forma incremental e intuitiva.
Principais componentes:
ggplot(): inicializa o gráfico
aes(): mapeamento estético (x, y, color, etc.)
geom_*(): tipo de gráfico (point, line, bar, etc.)
facet_*(): painéis múltiplos
theme_*(): aparência geral
scale_*(): controle de escalas
Exemplo:
Code
library(ggplot2)
Warning: pacote 'ggplot2' foi compilado no R versão 4.5.2
Code
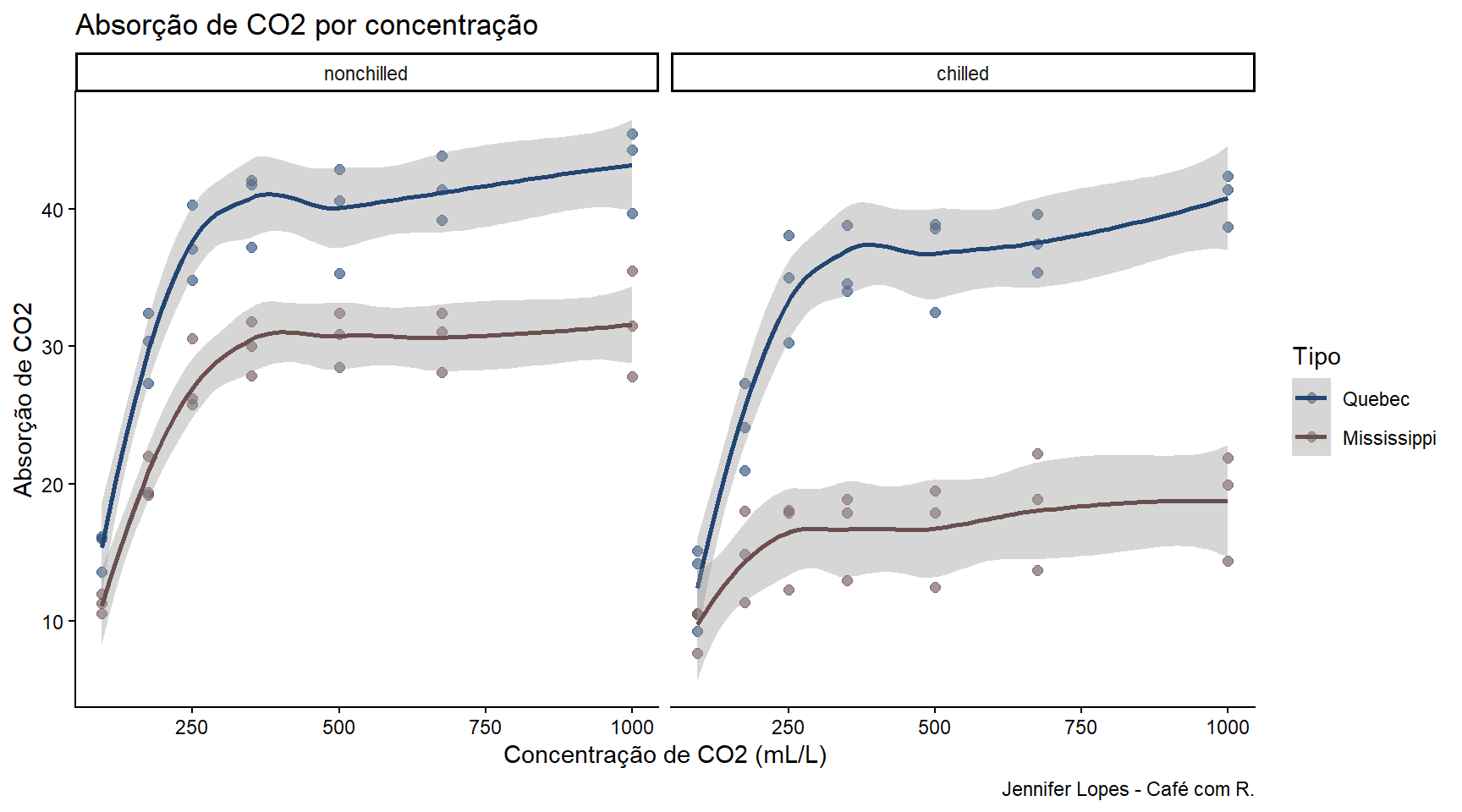
library(dplyr)# Usando dados CO2 do Rdata(CO2)# Gráfico de dispersão com linha de tendênciaggplot(CO2, aes(x = conc, y = uptake, color = Type)) +geom_point(alpha =0.6, size =2) +geom_smooth(method ="loess", se =TRUE) +facet_wrap(~Treatment) +scale_color_manual(values =c("#224573", "#6B4F4F")) +theme_classic() +labs(title ="Absorção de CO2 por concentração",x ="Concentração de CO2 (mL/L)",y ="Absorção de CO2",color ="Tipo", caption ="Jennifer Lopes - Café com R.")
Quando usar: Sempre! Visualização é fundamental em todas as etapas: exploração, análise e comunicação de resultados.
data.table : Performance com grandes volumes
Para quem trabalha com datasets grandes, o data.table é imbatível em velocidade. Sua sintaxe concisa pode parecer estranha no início, mas a performance compensa.
Principais características:
Extremamente rápido para filtros, agregações e joins
Modifica dados in-place (economia de memória)
Sintaxe: DT[i, j, by] onde i = linhas, j = colunas, by = agrupamento
Compatível com dplyr via dtplyr
Exemplo:
Code
library(data.table)
Warning: pacote 'data.table' foi compilado no R versão 4.5.2
Code
# Usando dados mtcarsDT <-as.data.table(mtcars)# Filtrar e sumarizarresultado <- DT[mpg >20, .(media_hp =mean(hp),total = .N), by = .(cyl, am)]print(resultado)
Quando usar: Datasets com 1 milhão+ de linhas, operações repetitivas, quando performance é crítica.
Quarto/RMarkdown : Relatórios reproduzíveis
Quarto é a nova geração de documentos dinâmicos (sucessor do RMarkdown). Permite criar relatórios, apresentações, websites e livros que misturam código, resultados e narrativa.
Principais recursos:
Múltiplos formatos de saída (HTML, PDF, Word, etc.)
Execução de código R, Python, Julia
Chunks de código configuráveis
Sistema de citações e referências
Temas e templates customizáveis
Exemplo:
---title: "Relatório de Vendas"author: "Seu Nome"date: todayformat: html: toc: true theme: cosmoexecute: echo: false warning: false---## Análise Mensal```{r}#| label: fig-vendas#| fig-cap: "Evolução das vendas mensais"library(ggplot2)data(CO2)ggplot(CO2, aes(x = conc, y = uptake)) +geom_col(fill ="#224573") +theme_minimal()```As vendas apresentaram crescimento consistente no período.
Quando usar: Relatórios que precisam ser atualizados regularmente, documentação de análises, compartilhamento de resultados.
DBI + dbplyr : Conexão com bancos de dados
Trabalhar diretamente com bancos SQL sem sair do R. O DBI fornece a interface de conexão e o dbplyr traduz código dplyr para SQL.
Principais funções:
dbConnect(): conecta ao banco
tbl(): referencia uma tabela
collect(): traz dados para R
compute(): cria tabela temporária
Queries dplyr traduzidas automaticamente
Exemplo:
Code
library(DBI)library(dbplyr)# Conectar ao PostgreSQLcon <-dbConnect( RPostgres::Postgres(),dbname ="vendas",host ="localhost",user ="usuario",password ="senha")# Trabalhar com tabela remotavendas_db <-tbl(con, "vendas")# Usar dplyr normalmente - operações acontecem no bancoresultado <- vendas_db |>filter(ano ==2025) |>group_by(produto) |>summarise(total =sum(valor, na.rm =TRUE)) |>collect() # Traz para R apenas o resultado# Ver SQL geradovendas_db |>filter(ano ==2025) |>show_query()# Sempre desconectar ao finaldbDisconnect(con)
Quando usar: Dados armazenados em bancos SQL, datasets muito grandes para carregar na memória.
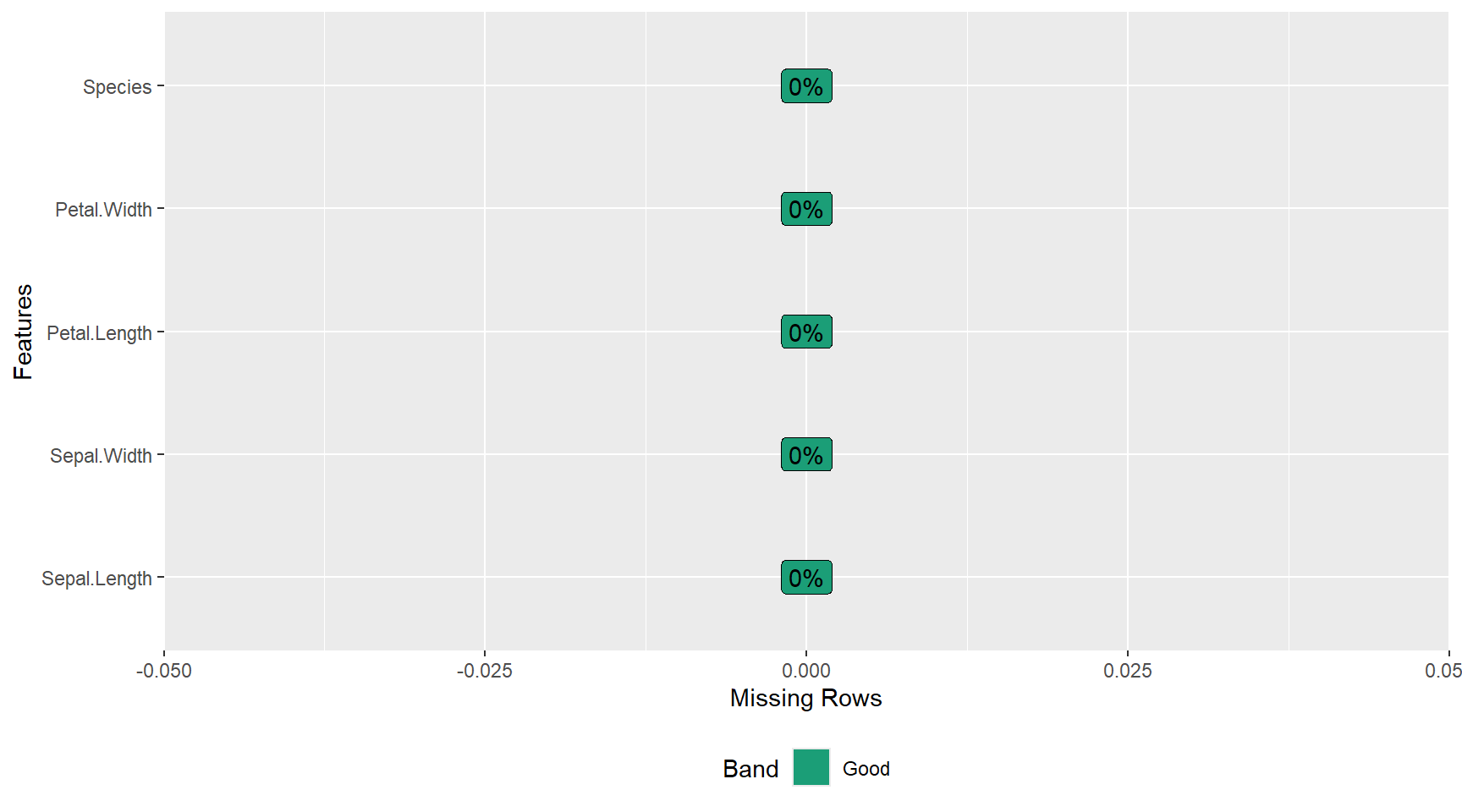
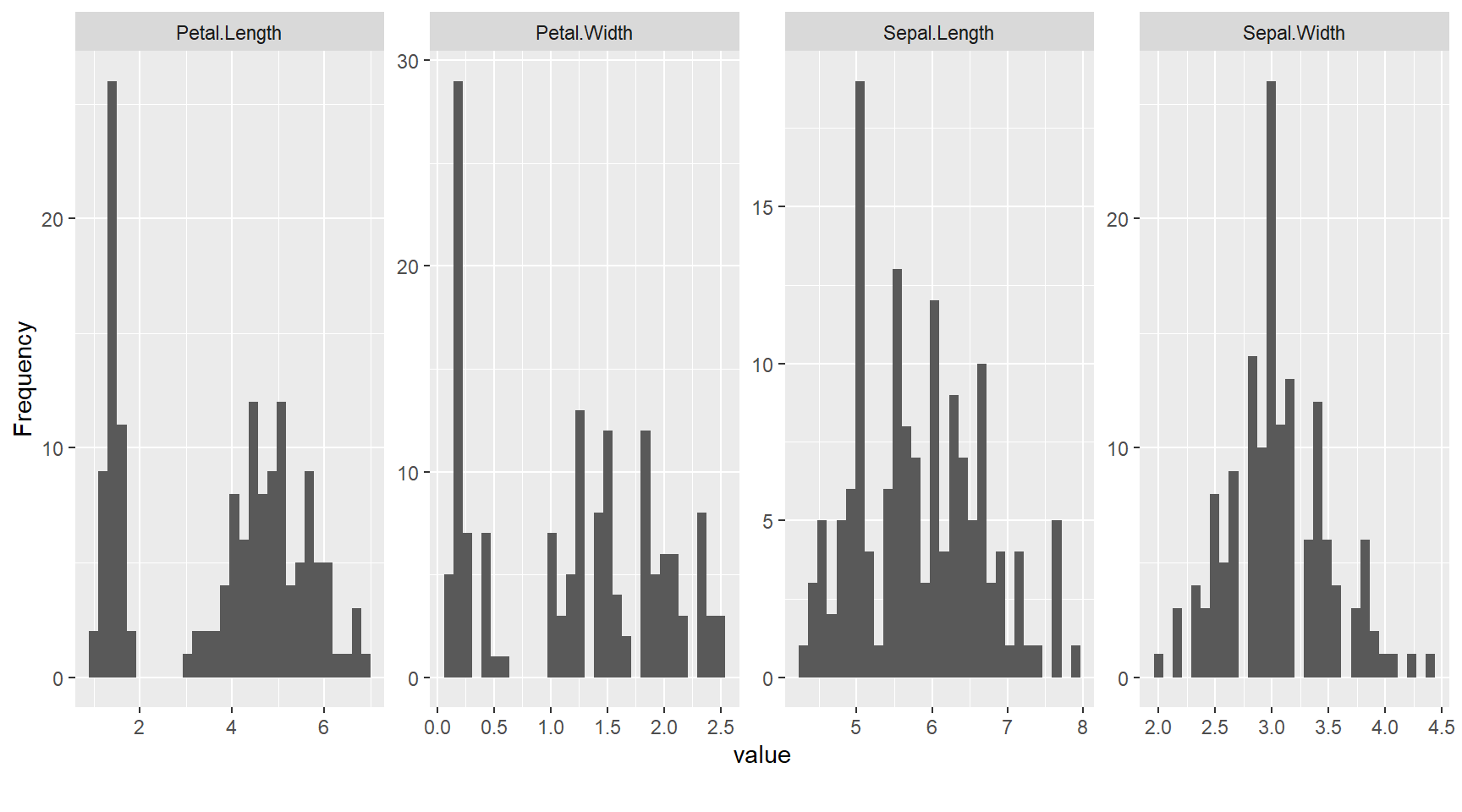
DataExplorer : Análise exploratória automática
O DataExplorer automatiza a análise exploratória de dados (EDA), gerando relatórios completos com estatísticas descritivas, gráficos e diagnósticos.
Principais funções:
create_report(): relatório completo automático
plot_missing(): visualiza dados faltantes
plot_histogram(): histogramas de todas variáveis
plot_correlation(): matriz de correlação
introduce(): resumo geral do dataset
Exemplo:
Code
library(DataExplorer)# Usando dados irisdata(iris)# Visão geral dos dadosintro <-introduce(iris)print(intro)
Quando usar: Início de projetos, primeiro contato com novos dados, relatórios rápidos para stakeholders.
tidymodels : Framework de Machine Learning
O tidymodels é um conjunto de pacotes para modelagem preditiva que segue os princípios do tidyverse. Substitui o antigo caret com uma abordagem mais moderna.
Quando usar: Modelagem preditiva, machine learning, comparação de modelos, tuning automatizado.
Para Acompanhar o Café
Recursos recomendados
Livros:
Sites
Reflexão da Semana
“A melhor ferramenta é aquela que você domina. Não tente aprender tudo de uma vez, escolha os pacotes que resolvem seus problemas atuais e vá expandindo conforme a necessidade.”
Começar com o básico (readr, dplyr, ggplot2) já resolve 80% dos problemas do dia a dia. Os demais pacotes você vai incorporando naturalmente conforme seus projetos evoluem.
Considerações finais!
Espero que este guia ajude você a escolher as ferramentas certas para cada etapa do seu trabalho com dados. Lembre-se: o importante não é conhecer todos os pacotes, mas usar bem aqueles que fazem sentido para seus projetos.
Compartilhe este conteúdo com quem está começando em R!
☕ Assine o Café com R
Que cada gole desperte uma nova ideia.
Que cada script abra uma nova conversa.
Que o Café com R, se torne um ponto de encontro nosso!